Project 03 · Local-first AI
Tutor Module
An AI tutor that runs entirely on your laptop. No API keys, no data leaving the machine, no per-token costs.
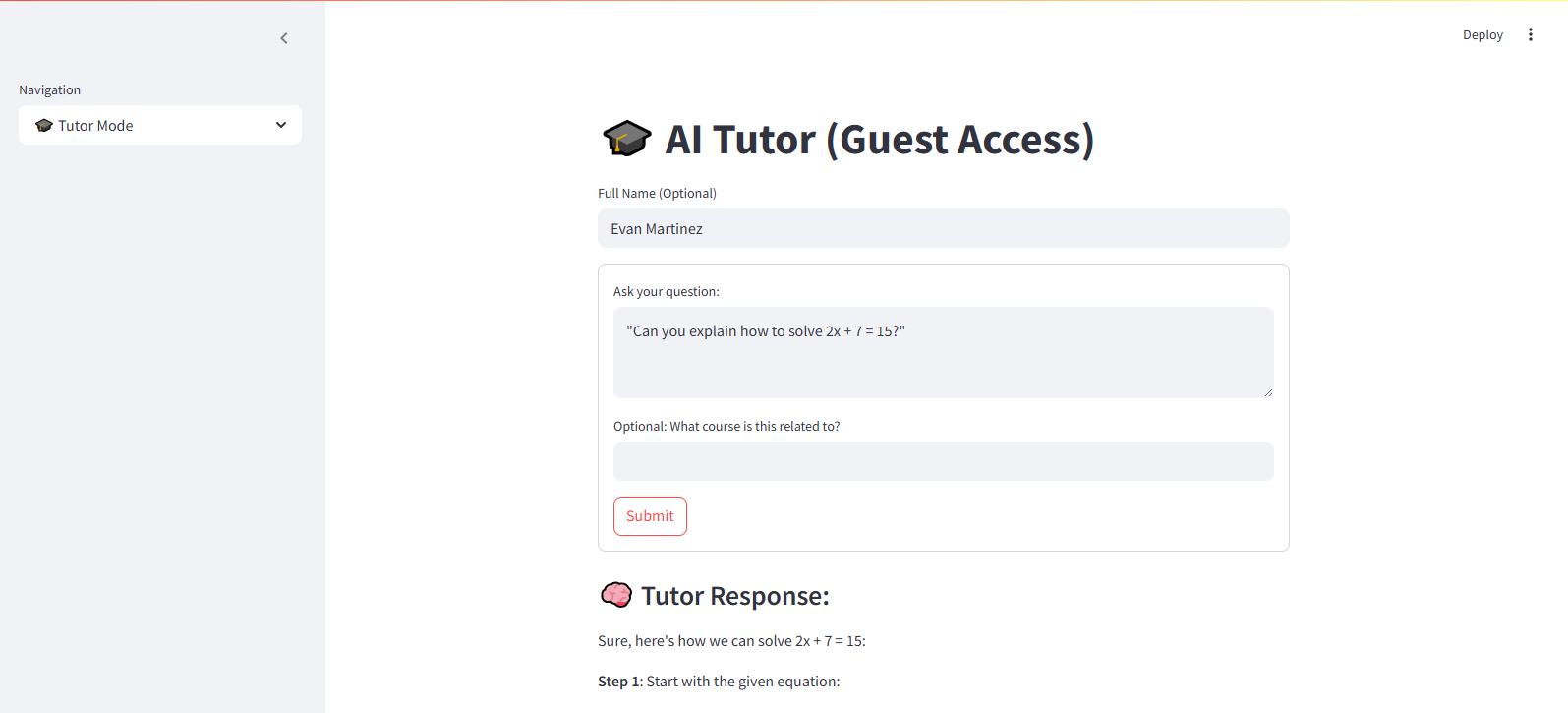
The Streamlit frontend. Students enter a question, optionally with a course tag, and the local model returns a step-by-step explanation.
The Problem
Most AI tutoring tools have the same architecture: send the student's question to OpenAI or Anthropic, get a response back, charge the institution per token. That model has two problems for higher education. The first is cost: per-token billing scales with usage, which means the tools that work best are the ones colleges use least. The second is data: a student's coursework question is education record data under FERPA, and routing it through a third-party API is a data-handling decision colleges have not always controlled well.
The original proposal for this project was to build a Canvas-integrated tutor for Miami Dade College using LlamaTutor and OATutor, with cloud deployment in a later phase. As I built, the more interesting question turned out to be a smaller one: can you run a tutor entirely on local hardware, without any external APIs at all? The current prototype is the answer to that question.
What I Built
The Tutor Module is a working AI tutor that answers student questions, recommends learning resources, and generates practice problems. It runs locally on a laptop or school server using a small open-weights language model (Gemma 3) hosted by Ollama.
- Conversational tutoring with step-by-step explanations adapted to subject and difficulty.
- Auto-detection of subject and concept from the student's question, so users don't have to manually classify what they're asking about.
- Curated resource recommendations. Each concept maps to a curated set of videos, articles, and practice material.
- Visual aids. Diagrams and interactive resources surfaced based on the topic.
- Practice question generation. The tutor can produce follow-up questions on the same concept after an explanation.
- Interaction history. Q&A logs are persisted per student for review and analytics.
- Two-way teaching. After an explanation, the tutor asks the student to respond in their own words. The follow-up prompts a check-for-understanding rather than just delivering an answer.
Two services, one app
The frontend is a Streamlit UI. The backend is a FastAPI service running on port 8500. The two communicate over HTTP, which means the UI could be swapped for something else (a React app, a mobile client, a Slack bot) without touching the backend. The backend itself talks to Ollama over HTTP as well, so the model is pluggable. Switching from Gemma 3 (4B) to a larger Llama 3 variant is a configuration change, not a code change.
Step-by-step response with check-for-understanding
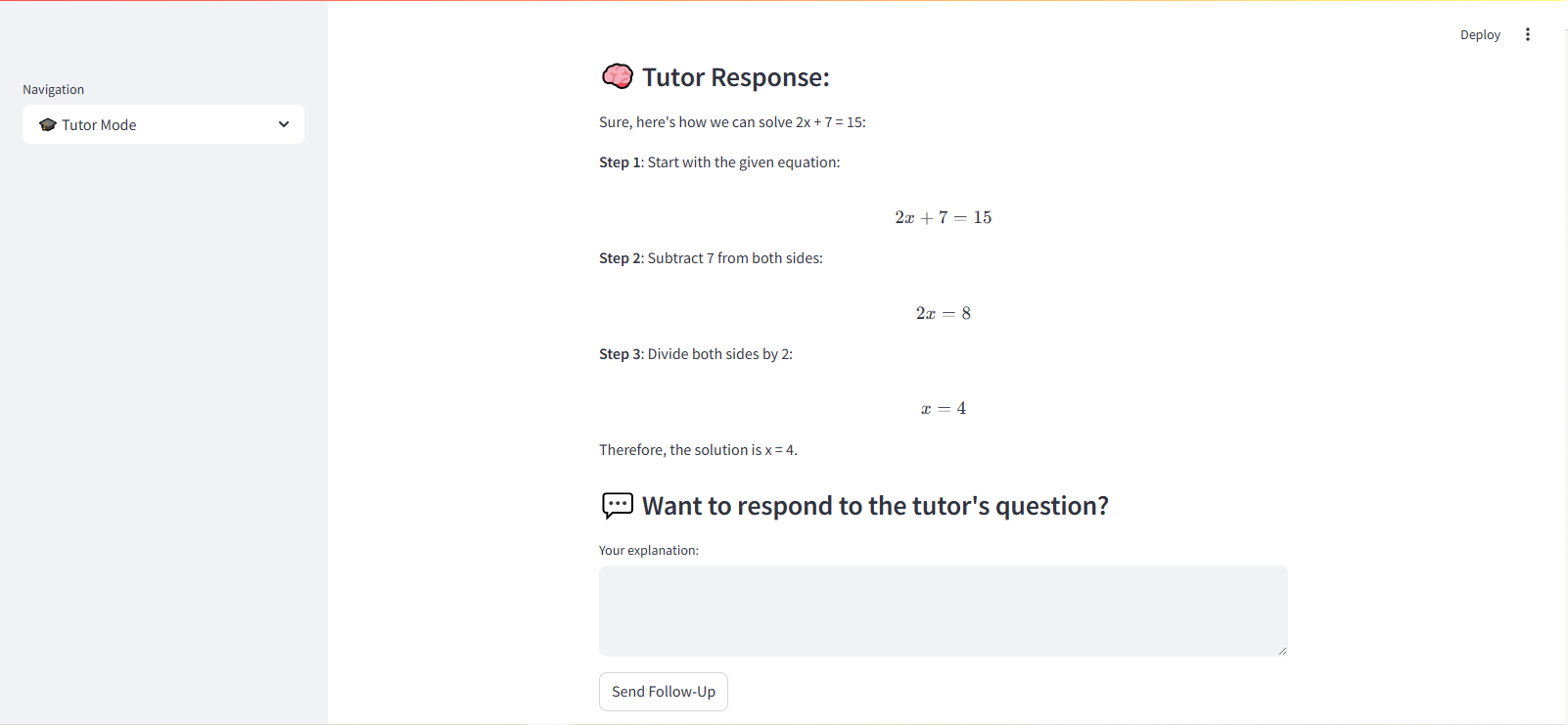
After an explanation, the tutor asks the student to respond in their own words. The follow-up is a check-for-understanding, not just an answer delivered.
How It's Built
FastAPI handles routing, validation, and orchestration on the backend. When a student asks a question, the request flows through subject and concept detection, then a prompt builder, then a resource lookup, then the call to the local model. The history logger writes the Q&A pair to a per-student file for later review.
Ollama runs Gemma 3 (4B) locally. The model is small enough to run on consumer hardware but capable enough for college-level tutoring tasks across math, English, and the sciences. The backend warms the model on startup so the first user request does not pay the cold-start cost.
Persistence is intentionally simple: JSON files for interaction history and student profiles. A SQLite migration is planned for the next iteration. The current approach is easy to inspect and easy to back up, which matters more than performance for a project at this scale.
Architecture
Streamlit UI → FastAPI Backend → Ollama (gemma3:4b)
(tutor_ui.py) (routes.py) (localhost:11434)
│
├──> Subject & concept detection
├──> Prompt builder (prompt_engine.py)
├──> Resource lookup (recommender.py)
└──> History logger (history.py)
Tech Stack
What I Learned
Building local-first AI is a different problem than building API-first AI. With OpenAI or Gemini, the model is somebody else's problem. Latency is somebody else's problem. Cold starts are somebody else's problem. With a local model, all of that becomes yours. I learned to warm the model on backend startup so the first request does not block, to keep the model small enough that it actually fits in memory on a teacher's laptop, and to think carefully about what gets sent to the model versus what gets handled in code. Subject and concept detection happen before the model is called, not by the model itself, because keyword matching in Python is faster and more predictable than asking a language model to classify.
Separating the UI from the backend was a deliberate architectural decision that paid off the first time I needed to test something. I could hit the FastAPI endpoints directly with the auto-generated docs at /docs without launching the Streamlit UI at all. That kind of separation matters more on a project where things are still moving than on a finished one. The two services can evolve independently, and either one can be replaced without rewriting the other.
The strongest lesson, though, is about what local-first actually means for EdTech. The architecture is the privacy story. There is no API key to leak, no third-party logging endpoint to misconfigure, no network egress for an institution's IT department to audit. The student question, the model response, and the history log all live on the same machine. For colleges and districts that have spent the last few years getting burned by SaaS vendors who quietly changed their data handling policies, that is not a feature. That is the whole pitch.
Next Project